dbt blues

When dbt Labs announced their merger with Fivetran, the data community had feelings. A lot of them. The dbt fear index—Oliver from Lightdash's brilliant term for the spike in repository forks—told the story better than any LinkedIn post could.
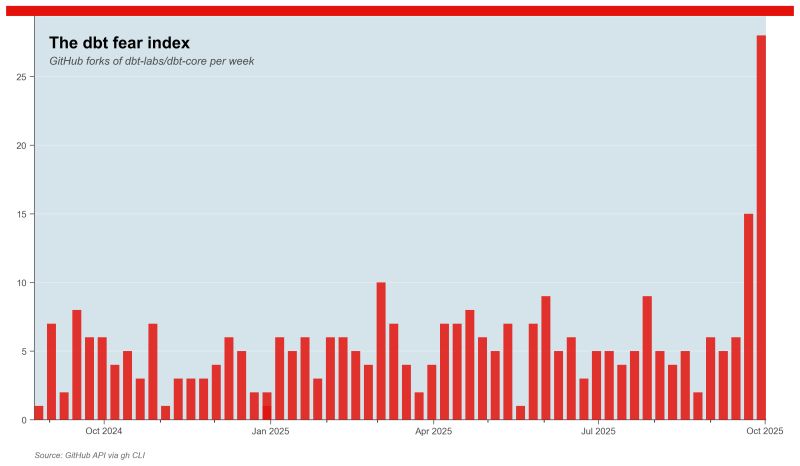
I'm not going to analyze the deal here. I'm not a finance expert, and frankly, Ethan Aaron already wrote the best summary of what happened: it's mostly about money, investment structures, and valuations that never quite added up.

That high valuation from the peak investment years? It was always hanging around dbt's neck.
But here's what I am interested in: this moment is giving people a glimpse of something they maybe forgot—open source isn't forever, and convenience isn't the same as fundamental.
dbt did something remarkable. It unlocked "modern" data stacks that probably wouldn't exist in their current form without it. The convenience layer it added wasn't just nice-to-have; it was transformative. But it was also always solving the easy problem, not the hard one. And understanding that difference explains where dbt came from, why it could never evolve beyond what it was, and what comes next.
Not for "the industry." For me. For the work I'm doing now.
This isn't really the blues. It's the end of one chapter and the beginning of another.
1. The Rise: dbt's convenience layer unlocked modern data stacks
Let me start with what dbt actually is, because I think people sometimes forget: at its core dbt is an SQL orchestrator.
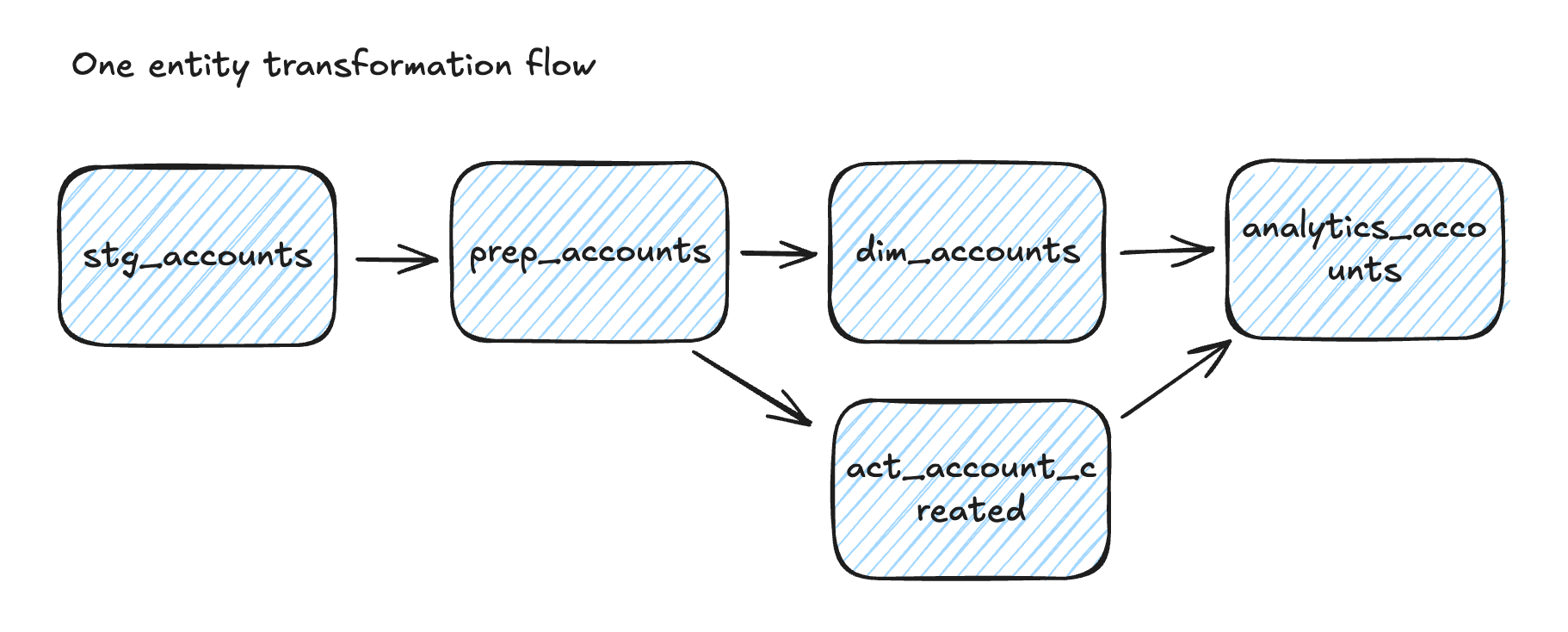
That's it. When you're building a data model—or really, just writing a set of queries—you need them to run in order. Five queries? You can schedule them in your database. But the moment you get beyond that, when query B depends on query A finishing first, manual scheduling falls apart fast. By the time you have 200 transformations, you need something that understands dependencies and can run everything in the right sequence.
Before dbt came around, people were solving this problem with home-built systems. I worked on two or three projects with custom implementations—basically, pre-dbt versions cobbled together to do the same thing. Fishtown Analytics had the same problem everyone else did. But they did something smart: they standardized it. They created a framework that was easy to understand, easy to adapt, easy to execute locally, and easy to run in production. The building blocks were clean.
That's why dbt got massive adoption so fast. Possibly the fastest-growing data application in the last 10 years. It solved an immediate, obvious problem that people already understood and desperately wanted help with. It wasn't revolutionary—it was the right standardization at the right time.
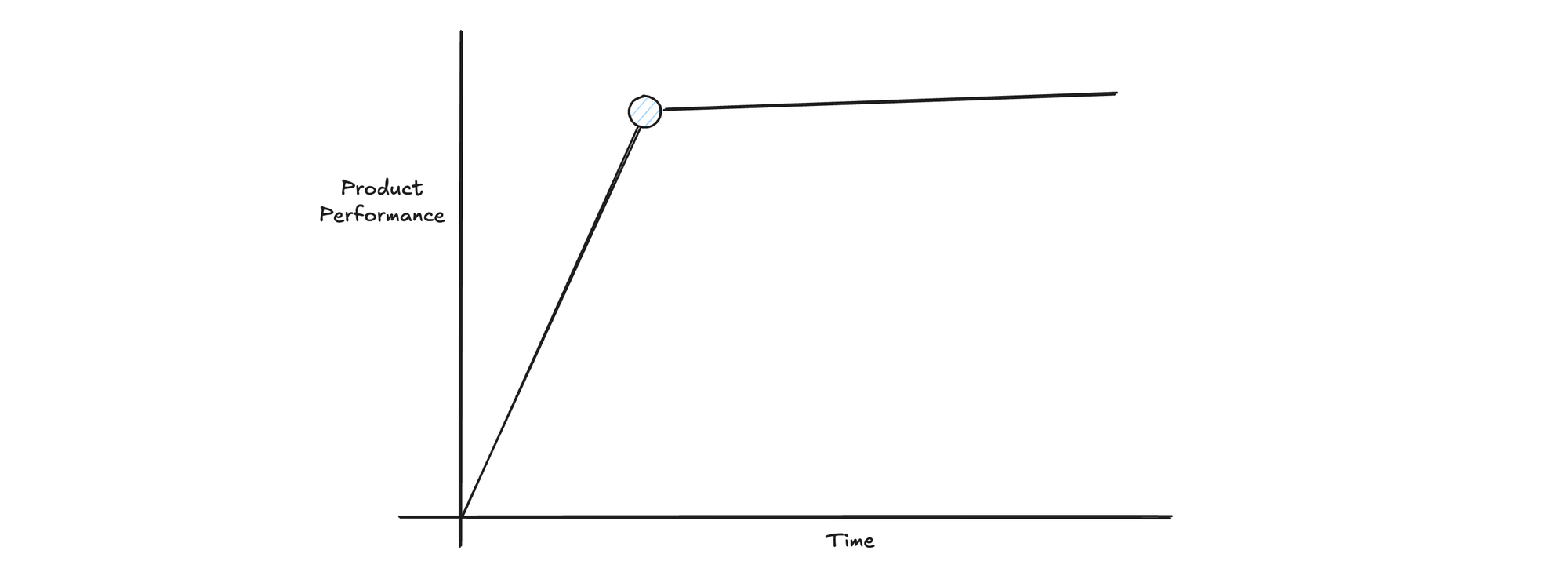
Peak 1: Product
From a product perspective, dbt peaked the moment it launched.
It nailed orchestration. The system was straightforward, easy to learn, reasonably easy to extend. People were thrilled. It was the missing puzzle piece.
And then... it never really went beyond that.
Don't get me wrong—they released features for dbt Core, and then there was dbt Cloud. But dbt Cloud was never an evolution of the product. It was a weird extension. A managed service that moved some things around: where jobs run, maybe a slightly smoother developer experience for teams working on the same codebase. But running jobs was never really a big problem for most companies. Setting up a build job in GitHub Actions is pretty straightforward. The developer experience? Sure, if you've got a 50-person team, dbt Cloud might smooth out some configuration headaches. But the implementation never felt well-executed.
And here's the thing: analytics engineering is often tedious. Debugging can eat hours. There was—and still is—space to solve real problems in that process. dbt never did.
That's why I say they peaked at launch. They solved orchestration brilliantly and then plateaued. Maybe that explains why we're here now, with a merger instead of a Snowflake-level trajectory. They never created a product that became valuable enough that people would happily pay serious money for it.
Peak 2: Community
The community peak might have been the most significant one. And I'd guess it happened initially by accident.
There was this huge void in the data space. People doing data engineering, writing SQL, maintaining data models, running ad hoc queries—they had nowhere to ask questions, to come together. It's complex work. There are so many questions. And a lot of new people were starting to build data setups. And suddenly, dbt wasn't just a tool; the dbt community became the place to ask those questions.
What the dbt team did early on was excellent: open office hours, the early Coalesce conferences, local dbt meetups, dbt blogs. It was all practitioner-driven. The vibe was good. The content quality was high. It created this backbone where people developed real affection—maybe even love—for the tool.
The local user groups are still good. Coalesce eventually shifted more enterprise, which is probably natural, but that early energy? That was special. They discovered the community and then facilitated it beautifully.
Peak 3: The Standard
All of that led to the third peak: dbt became a standard.
When I talk to enterprise clients now, I don't have to explain what dbt is. They've heard of it. Maybe they've tried it. Maybe they're using it. Even if they're not, I don't have a hard sell when I say, "We should run dbt here—orchestrating transformations is real work, and dbt makes it straightforward." That's an easy conversation in environments where things usually sell hard.
dbt became a standard. But what kind of standard?
Here's the question nobody can really answer. Fivetran was the ETL standard for a some few years—especially for loading generic datasets. Then it diluted, other tools came in. But dbt is still in stack definitions. Still showing up in conversations. People say things like, "We use dbt for our data model."
Except... they don't. Not really. And this is where things get interesting.
The convenience that unlocked everything
Some People say dbt is a standard for data modeling. It's not. It could never be.
The data model itself is a design. It happens on a whiteboard. It's decisions about structure, relationships, and logic. dbt can represent some of that structure—how you organize your queries, how you break down your transformations. But dbt is an executor, not the modeling layer.
You use dbt to physically execute or process the data model. It runs the transformations. It makes sure they happen in order. That's orchestration, not modeling.
But here's what dbt did do: it made orchestration convenient enough that teams could actually build and maintain sophisticated data operations. Without that convenience layer, most modern data stacks wouldn't exist in their current form. The barrier to entry would have been too high. Teams would have gotten stuck in the mess of custom solutions and given up, or they'd have thrown their hands up and said, "We'll just use scheduled queries and hope for the best."
dbt lowered the barrier. It standardized the approach. It made analytics engineering accessible at scale. That convenience wasn't a nice-to-have—it was transformative. It unlocked an entire wave of data work.
That impact was real. And we should recognize it.
2. The Ceiling: Why dbt could never evolve beyond convenience
Let me explain my view why dbt was never going to become Snowflake.
Snowflake, BigQuery, Redshift, Databricks—they solve a fundamental problem. You need to store massive amounts of data somewhere. You need to query that data in a cost-effective way. Without that capability, the entire data use case collapses (or changes in its form). Take those services away, and you've taken the whole solution away.
That's what makes them fundamental.
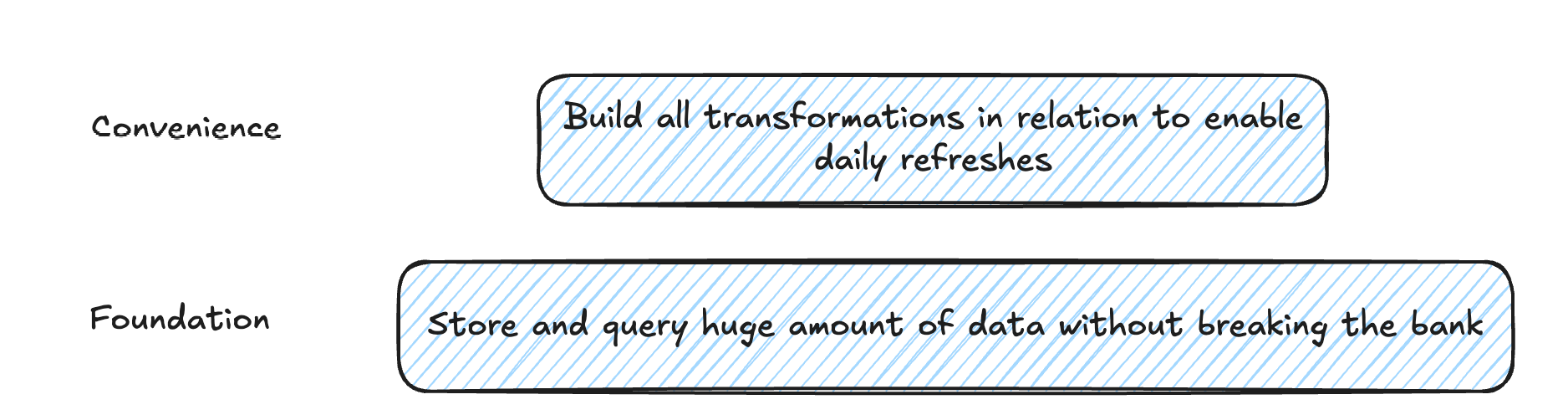
Is dbt fundamental? Not really.
You can always work around it
Technically, we're just running SQL queries. We've been running SQL queries forever, in different ways. You can schedule them—yes, that doesn't work if you have 200 or 1,000 transformations, but it works for simpler setups. Or you can use a generic orchestrator. When dbt got started, people were already using tools like Jenkins. Airflow exists. You can run all your SQL in there.
dbt made it easier. The dependency management, the testing framework, the documentation—it was all more convenient. But there's no absolute need for it.
If you took dbt away from every data team tomorrow, they'd come up with a solution in four to six weeks. You could extract the compiled SQL. You could literally have an intern run it every morning if you wanted. Or—and maybe this is the better option—you'd use it as an opportunity to redesign your data model, because maybe the reason it got so complex in the first place is that you kept layering transformations on top of transformations without stopping to ask if there was a simpler way.
This is the part dbt never solved. Teams could always work around it. And if dbt became too expensive? They'd find that workaround fast.
That's why dbt never became something people were willing to invest massive amounts of money in. It's convenience, not necessity.
The problem dbt never solved
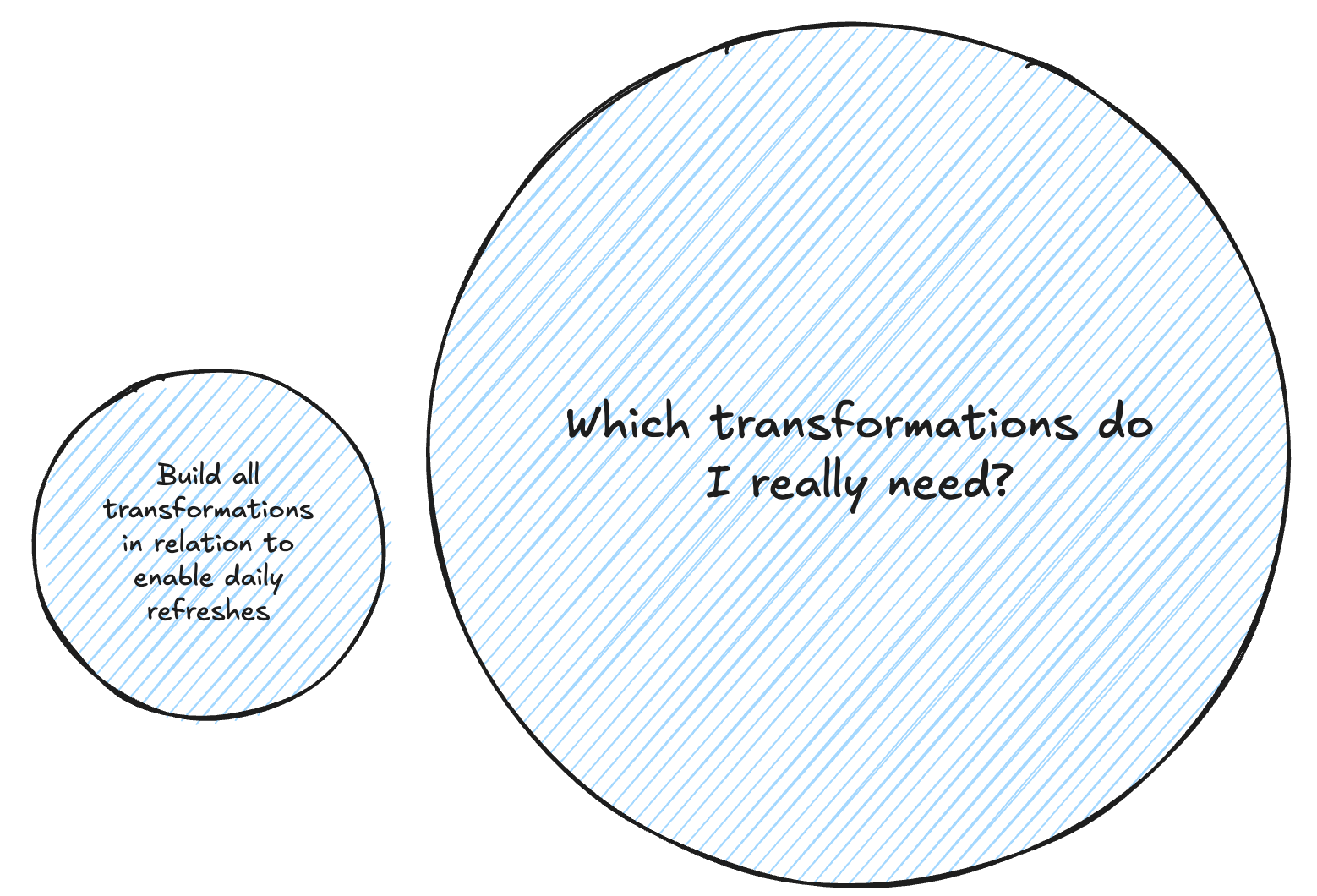
Everyone understood the benefit of dbt: orchestrating transformations. Dependencies handled. Tests in place. Documentation generated. Great.
But dbt never answered the harder question: What transformations do I actually need to do?
And that's the problem that actually matters.
When you have 1,000 transformations in your data model, maintaining it is hell. Ensuring data quality across that many moving pieces? It's a job you can only lose. Something will break. Something will drift. Some assumption someone made six months ago will turn out to be wrong, and you'll spend days tracking it down.
dbt tried to help with data quality tests. You could add tests to check for nulls, for uniqueness, for referential integrity. But tests are reactive. They tell you something broke. They don't prevent you from building an unmaintainable mess in the first place.
The core problem is the transformations themselves. How many do you actually need? How should they be structured? What's the right level of granularity? When should you merge logic, and when should you split it apart? These are design questions, and dbt doesn't help you answer them.
It can't. It's an executor. It runs what you tell it to run. (Snowflake btw, also doesn't answer these, but it is one layer down, far away to think about it).
People kept saying they were "using dbt for data modeling," but they were really using dbt to execute a data model they'd designed somewhere else—on a whiteboard, in their head, through trial and error. The modeling itself? That was still hard. dbt didn't make it easier.
Why it could never evolve
This explains why dbt peaked at launch and never really went beyond it.
Orchestration was the "easy" problem. dbt nailed it. But once you've nailed orchestration, where do you go? You can add features—testing, documentation, packages, macros—but those are all extensions of the same core capability. They don't change the fundamental value proposition.
To evolve beyond that, dbt would have needed to solve the hard problem: transformation design. How do you help teams build maintainable data models? How do you guide decisions about what transformations to create? How do you make the design process itself better?
That's a much harder product to build. It requires a different approach, different primitives, maybe even a different mental model. And dbt was never structured to do that. It was built to orchestrate SQL, and it did that well.
But "orchestrate SQL well" has a ceiling. You hit it pretty fast.
The merger makes sense now
When you look at it this way, the Fivetran merger makes more sense. dbt couldn't become Snowflake-level valuable because it wasn't Snowflake-level fundamental. It was a convenience layer on top of something teams could always do another way. The same what Fivetran is now.
That high valuation from the peak investment years? It was always a weight around their neck. How do you grow into a valuation that assumes you're solving a more fundamental problem than you actually are?
You don't. You find a different path.
The community loved dbt. The product worked. But love and functionality don't necessarily translate to the kind of revenue that justifies a massive valuation. Especially when your customers know, in the back of their minds, that they could work around you if they had to.
That's not a criticism of dbt. It's just the reality of what they were solving.
And maybe—just maybe—that's okay. Because the fact that dbt was a convenience layer, not a fundamental piece of infrastructure, means we're free to move on when something different comes along.
3. My Next Iteration: Moving beyond orchestration to meta models
The core layer is shifting. Data engineers are working on the next iteration of how we store and query data. Turns out, even models like Snowflake and BigQuery have limitations when you're dealing with the scale they enabled. More use cases mean more data, more queries, more compute. At some point, the bills start growing faster than the business value, and engineers start looking for ways to handle even bigger datasets more effectively.
You can follow this rabbit hole if you want—experiments with table formats like Iceberg, what's happening with DuckDB and Duck Lake. It's fascinating. The paradigm of how data gets stored and queried might change significantly over the next five years. It's already starting.
And just like dbt was only possible because Snowflake, BigQuery, and Redshift created new use cases, these new fundamentals will create space for new approaches. New tools. New ways of thinking about the problem.
But for me, the question isn't about what tools come next for everyone. It's about what comes next for the work I'm doing.
The problem dbt never touched
There's something dbt unlocked but never addressed: metadata management. How we approach data modeling and transformation design at a higher level. And tbf - these approaches and tools existed before and next to dbt. But just for a much smaller audience.
dbt let you write a lot of transformations. It chained them together. It ran them in the right order. It gave you some helpers—DRY principles through macros and packages—but anyone who's worked with macros knows that was never ideal. It was functional, but clunky.
Metadata models that generate data models aren't new. They existed before dbt. But they were never really accessible to most people—usually proprietary software, expensive, hard to work with.
And that's the problem: a 1,000-transformation model is hard to maintain. That's not a surprise. If you want to ensure data quality across 1,000 transformations, it's basically a job you can only lose. You can't win.
So the question becomes: how do you avoid building/maintaining 1,000 manual transformations in the first place?
My current experiments: standardization and meta layers
I don't have a universal answer. I have an answer for myself. At least what I want to test more.
I work with a very standardized approach to building data models. I do similar projects—mostly in the growth area, combining event data with product usage, marketing attribution, and subscription metrics. Over time, I've developed a standardized data model for these setups. I know what the structure looks like. I know what the entities are. I know how they relate to each other.
What I'm doing now is building a meta layer on top of that standardization. It makes it easier to define the inputs—what entities we're looking at, how they're configured, what properties matter. Then I let the meta model generate the output.
Right now, that output is dbt. I'm basically putting a layer on top of dbt. But here's the thing: it doesn't actually matter if it's dbt or not. I could extend it to output Airflow configurations, or Dagster, or whatever. The meta layer is what I'm managing. The orchestration is just... there.
And that's when I realized: I don't really need a transformation orchestrator anymore. I just need an orchestrator. Something that runs things in the right order. That's it.
Agentic workflows and configuration-as-code
There's another piece to this that I'm still exploring: agentic analytics engineering.
When you work with a meta model, you're working with typed entities. You define clearly how an entity should be transformed, how it should be built up. Everything is configured in code—not SQL you write by hand, but configuration that generates the SQL.
That makes it much easier to build agentic workflows. You can tell an agent, "Here's the entity structure. Here's the configuration format. Generate the transformation for this new entity based on these parameters." The agent doesn't need to write perfect SQL from scratch. It needs to fill in a configuration template.
Simon has written about this in a really good way:

He comes to the same conclusion: when everything is configured in code, you don't need a transformation orchestrator.
dbt got us here
None of this would be possible without dbt.
dbt made analytics engineering accessible. It created the space for people to think about these problems. It matured the practice enough that we can now see what the next level looks like.
I'm not trying to predict "the next wave" for the industry. I'm just describing my next iteration. What I'm building for the work I'm doing now. And I can only do it because dbt existed, because it unlocked this whole space, because it gave me a foundation to build on.
But I don't need dbt anymore. Not for what I'm trying to do next.
Not the blues—the beginning
So when I see people panicking about the dbt/Fivetran merger, when I see the dbt fear index spiking, I get it. Change is uncomfortable. The thing you relied on feels less stable.
But this isn't really something to mourn.
dbt did its job. It was the essential bridge that got us here. It unlocked modern data stacks. It created a community. It gave us the space to experiment and grow and figure out what we actually needed.
And now? Now we're ready for what comes next. For me, that's meta models and agentic workflows. For you, it might be something else. But we're all past the point where we need a transformation orchestrator to solve the hard problem.
The hard problem is transformation design - data models. And we're finally mature enough to start tackling it (ok, tbf - enough people were mature enough all the time).
That's not the blues.
Join the newsletter
Get bi-weekly insights on analytics, event data, and metric frameworks.